Wearing a face mask against COVID-19
History / Edit / PDF / EPUB / BIB / 2 min read (~202 words)Should I wear a face mask against COVID-19 if I'm not sick?
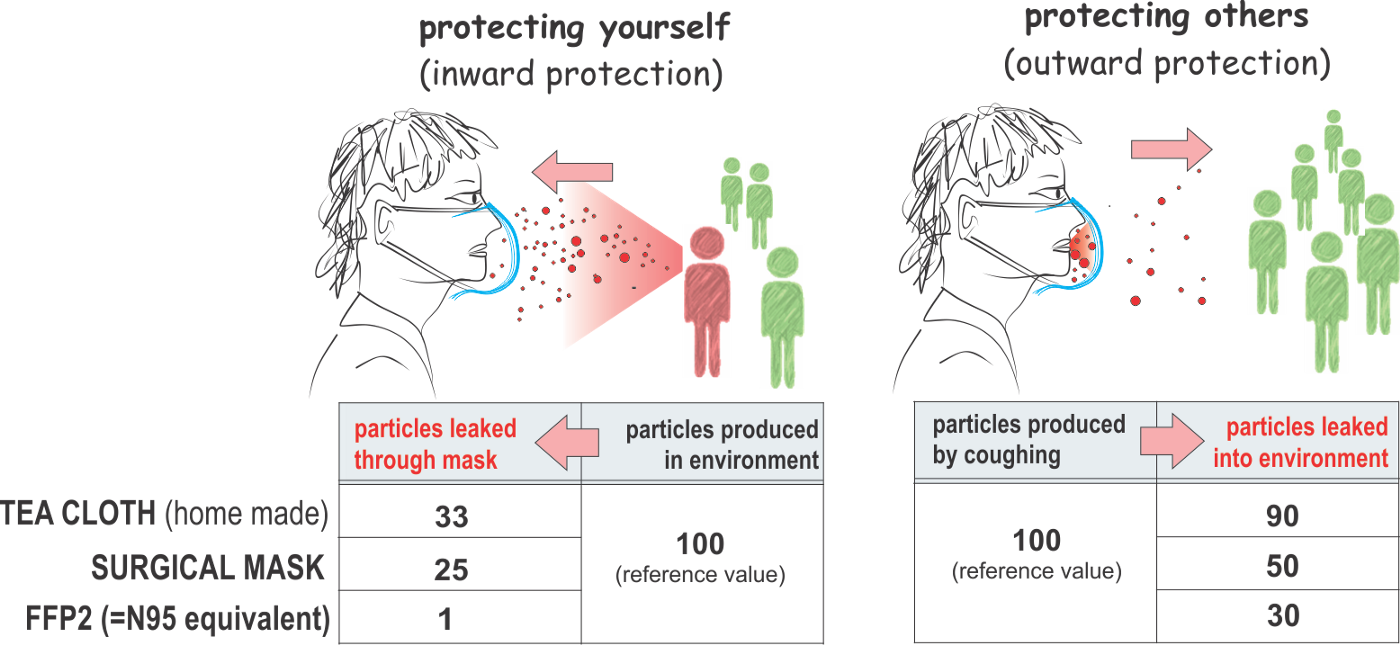
If you have masks already, wear one. It will protect you from others and others from you.
The official answer from the Government of Canada and the CDC is that wearing a face mask is not an effective solution to protect yourself against the virus.
If you are sick and you need to go out in public, wearing a face mask will help reduce the chances of spreading the virus to others.
If you want to avoid being ill due to the virus, the best way to do so is to avoid being exposed to the virus. This means staying at home in isolation.
- https://www.canada.ca/en/public-health/services/diseases/2019-novel-coronavirus-infection/prevention-risks.html#wm
- https://www.theguardian.com/world/2020/mar/15/can-a-face-mask-stop-coronavirus-covid-19-facts-checked
- https://www.livescience.com/face-mask-new-coronavirus.html
- https://time.com/5794729/coronavirus-face-masks/
- https://www.businessinsider.com/wuhan-coronavirus-face-masks-not-entirely-effective-2020-1
- https://www.cdc.gov/coronavirus/2019-ncov/about/prevention.html
Criteria for using a library in a project
History / Edit / PDF / EPUB / BIB / 1 min read (~119 words)What do I look for in a library before using it in a project?
It has to be maintained so that I know that issues are addressed.
It has to be supported so that I know I'll get help if needed.
It has to be highly used compared to other solutions to ensure it's more feature complete and of good quality compare to other libraries.
It has documentation so that I don't have to read the documentation to know how to use the library for common cases.
It has to have a simple API that does what I need so that I don't have to deal with weird/incomplete API that do half of what I need.
How can I reduce my error rate when using my skills?
When using skills in which you can make mistakes, it is important to monitor what you do and where you make your mistakes. Like any performance optimization problem, you want to figure out where you make the most mistakes and where you'll benefit the most from fixing those mistakes. If you make the same mistakes 100 times at the cost of a minute each time, that may be preferable to making 1 mistake that cost 100 minutes to fix, given that once the mistake happens, the cost stays the same.
Document your skills. Write down what you do, when you do it (triggers) and what kind errors you make during those steps. Evaluate how many times you make that mistake and how long it costs to fix. Then when you use your skills, track when you make mistakes and how long it takes you to fix the mistake.
As an example, think of a software engineer doing code reviews. Reviewing code requires going through a variety of checks: is the build passing? is the functionality properly implemented? are there tests? are the new files in the proper location? Without a list, the engineer is left looking at the code without any clear checklist. If he is methodical he will have a list he goes through in his head. If not, then he will most likely only look at the code and give it a summary opinion, that is, whether he likes what he sees, or not.
Given a non-explicit methodology it is hard to assess where the mistakes are made and which mistakes cost the most to fix. If you don't check that tests were written for the new functionality or changes, what impact will it have in the future? Depending on how likely the code is to change, the likelihood that something gets broken may be significant. While adding a test may require a few minutes, one has to judge how much time would be wasted if a bug were introduced in the piece of code. As code complexity increases, so does the cost of fixing issues in that code.
With an explicit checklist you will be able to track the things that you want to verify before code is merged. As your checklist covers more and more cases, this list will reduce the likelihood that the person who wrote code made a mistake that gets to production. By the same token it will increase your effectiveness as a software engineer to produce quality code.
Extracting someone's beliefs from their writings
History / Edit / PDF / EPUB / BIB / 2 min read (~304 words)Is it possible to extract someone's beliefs by reading their writings?
Yes.
If someone has written a blog for example, it is possible to figure out a variety of information about them simply based on what is written in those articles.
If someone writes about a specific software, we may not be able to infer right away what they think about said software, but we know that they've spent enough time to learn a bit about this specific software. If we know all the other alternatives in this category of software, we could infer that the user believes that this software is possibly better than the alternatives, otherwise why would they have picked it?
If the writer writes a lot on a topic, that is also a clue about their beliefs. They probably think that this topic is important, hence why they write about it. Maybe they write about this topic because it is lucrative to them.
What the writer doesn't write about is also informative. If they write mostly about technology, maybe they don't care about politics or sports?
It is possible to extract if-then rules from their writings, which generally expresses some form of believe that if something then something else. There are other variants where only if is provided (if something, something else, or something else, if something).
A writer may use certain adjectives to describe things as "easy", "simple", "straightforward", "difficult", "impossible", "hard", etc. Those are also useful of indicators of the writer's beliefs.
Nowadays with LLMs it's easy to provide a prompt such as "What beliefs are expressed in the following text" or "Extract the beliefs in the following text". With a bit of scripting we can extract everything available on the blog and feed it to a LLM to let it extract the beliefs for us.
As an AI developer, what skills do I use the most at work?
The following list is ordered according to the importance I give to those skills in my success at work.
- Analysis/understanding the problems: There's no point in doing work if you don't know why you're doing it. Understanding why you are solving a specific problem will give you insights on the best way to solve the problem itself using the right approach.
- Programming: I'm a software developer, so I spend most of my time (or hope I am) on writing code. That also includes reading code written by others.
- Prioritization: I need to decide what tasks are more important than other tasks and organize the list of tasks from most to least important. At my current job, it's everyone's responsibility to decide what is important to build.
- Time management: I have a variety of responsibilities so I need to juggle between them and the time I allocate to them. I also need to accomplish certain tasks according to deadlines, so it is important to properly manage my time, what gets done and when it gets done.
- Design/code organization: Programming is more than science. You also need to think about how the different parts of the code interact with each other and how to organize the code so that it is easy for others to understand the code and to participate in its development.
- Negotiation: Working in an organization means negotiating with others to make your ideas heard, accepted and developed. Not everyone will agree with your ideas, so you need to spend time and effort to convince others that your idea is the best.
- Scheduling: While time management is about making sure that you're spending your time on a task at the right moment, scheduling is about organizing your use of time with others in the company. It is about scheduling meetings and or events.
- Delegation: Being able to offload work to others is important. It is however a difficult skill because you need to be able to properly communicate with others what needs to be done and the expectations that you have (or that others have) regarding the completion of the task.
- Debugging: I love playing detective when there are issues in the code I maintain. I've acquired over the years a good ability to understand a system and to quickly pinpoint the cause of a bug or low performing system.
- Communication: Work is largely exchanging information and aligning with your coworkers. The most important skill of communication is listening because you want to understand first before saying anything.