I'm learning a language using Anki flash cards and I'd like to record my progress over time. I'd like to be able to hear what I sounded like when I started learning.
In 2017 I started learning Chinese. It was quite difficult for me given that I had very little prior experience with Asian languages, other than learning a bit of Japanese through a Rosetta Stone program where I couldn't figure out what they wanted me to learn based on images alone (they were trying to teach me color, but it was not obvious).
I imported the Memrise Mandarin Chinese flashcards level 1, 2 and 3 through the use of an Anki extension (https://github.com/wilddom/memrise2anki-extension) and I started my journey to learn. After practicing for a few weeks, I started being interested to have some form of recording of my progress, so I thought I could simply record my voice when I was asked to recall a word. Anki already had a recorder as part of its features so I simply piggy-backed on it to implement an Anki extension which I called the Anki recorder.
When a new card is shown to you, the recorder starts right away. As you recall the word, you have to pronounce it. Once you've said the word, you can then check if you were correct or not, at which point the recording is stopped. Each record is timestamped, which allows you to listen to any of the words over time. It's rather funny to listen to yourself when you started learning a language and how you sound a few years later.
With this tool I was able to record over 193k audio samples over 3 years. There's a good chunk of those records that is only silence because it would also be triggered on cards with text only (where you had to remember how to write the word, or what the word meant).
Hopefully this tool can allow you to record your language learning progression and have fun after a few months of practice!
Why do I track how much time I read and how many pages I've read?
It allows me to have an idea of how long a book will take me to read. It also allows me to determine over time if I'm getting slower or faster reading books by using a website like How Long to Read. While the website says that reading a book such as Liu Cixin's Death's End should take 10h to read to the average reader at 300 WPM, it took me more than 20h to read it, which means I'm a very slow reader and that I read at less than 150 WPM.
The benefit of knowing how long a book will take me to read is that I can decide if I want to actually spend that time finishing the book or not. When a book is good, this question is not considered, but when it is bad, it is important to decide whether spending more time is a worthwhile use of my time.
I wrote some new code or edited code in my PHP application and I'd like to know if this change is covered by tests.
The approach I thought of to solve this problem was to write your change, run your tests (most likely using PHPUnit), then create a diff/patch of those changes and use this information to determine whether the lines that are part of the diff are covered. It should be relatively straightforward to automate the process of generating a patch from within a git repository as well as running PHPUnit within a project's directory (generating a clover.xml report). With this information in hand, it would be possible for a script to compute what is and isn't covered by tests in the changes that you are about to commit.
I wrote PHP Code Coverage Verifier which takes care of reading the PHPUnit output (a clover.xml file) and a generated patch file and produce a report of the lines that are and aren't covered.
An example of the script output is as follow:
php vendor/bin/php-code-coverage-verifier verify my-clover.xml my-diff.patch
Using clover-xml file: my-clover.xml
With diff file: my-diff.patch
Covered:
controller/admin/stocks.php line 15 - 21
controller/admin/stocks.php line 91 - 97
controller/search.php line 26 - 32
controller/search.php line 376 - 384
model/user.php line 34 - 41
model/user.php line 44 - 51
Not covered:
controller/account.php line 39 - 45
controller/admin/stocks.php line 27 - 33
controller/search.php line 36 - 42
controller/search.php line 187 - 193
model/user.php line 533 - 540
Ignored:
application/composer.json
Coverage: 40 covered (56.338%), 31 not covered (43.662%)Questions and problems articles writing process
History / Edit / PDF / EPUB / BIB / 2 min read (~201 words)How do I write my questions and problems articles?
The process I use to write both my questions articles and my problems articles is quite similar, so I will summarize both in this article.
The process is as follows:
- Find the question or problem to cover.
- To find questions, I will look at the notes I have taken in the past and search for question marks. I answer those questions as a way to stimulate my brain to think about questions I may rarely have the time to answer.
- To find problems, I will look at my GitHub repositories. When I encounter a problem at work, I try to write it down so I can describe the issue in more details, which may hopefully help someone in a similar situation in the future.
- Think about the question or problem for a little while, to see what I can come up with.
- Write a list of items that I want to cover, this acts as my plan.
- Describe the items in the list in more details.
- Reference articles I've already written on the same topic.
- Review the article using LLMs for grammatical mistakes and typos.
I'm a tab hoarder and I would like to keep my tab count under control. How do I do that?
In January 2015 I wrote an extension for Chrome that allowed me to track how many tabs I had open. I called it the Chrome tabs count extension. It displays the number of currently opened tabs in the extension bar and when you click on the extension button itself, a chart is displayed with shows the tabs and windows count at each point a tab was opened/closed. This allows you to see the patterns of tabs creation/closing you have.
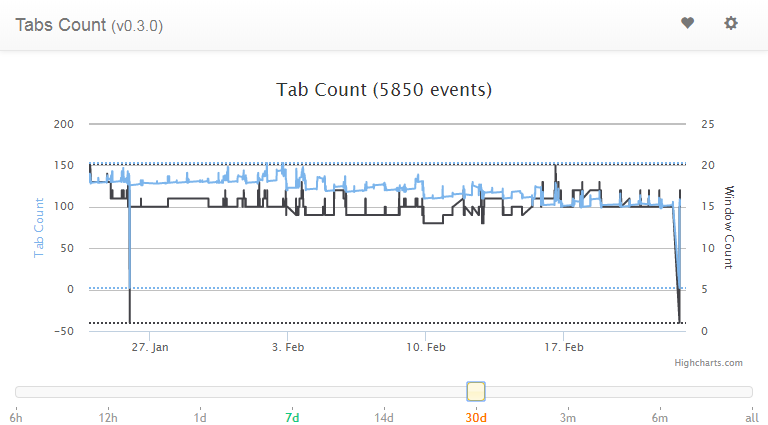
Such a tool will not help you reduce your tab count, but awareness is the first step toward reducing the number of tabs you have open at all times.
The second step is to taper (slowly reduce) the number of tabs you have open at all times. My strategy has been to reduce by 10 tabs each week the maximum number of tabs I had open. I started with over 160 tabs and I am now at 100 tabs after 6 weeks. I use the Loop Habit Tracker app to set up a daily reminder to make sure my tabs count is under the limit specified for this week and I try as hard as possible to finish the day with the number of tabs open below or at this limit.